


MySQL教程(9)视图、触发器与存储过程
一、数据库视图
数据库视图是将查询语句进行封装而形成的虚拟表,这些虚拟表可以用于正常的查询和修改操作
1、视图的应用场景
· 将复杂的查询语句进行封装,简化查询命令
· 可以灵活的对一些敏感表中的特定字段进行暴露,起到一个为不同用户提供定制化权限的作用
2、视图的种类
按数据存储方式可以将视图分为逻辑视图和物化视图,在大多数情况下提到的视图都是指逻辑视图,逻辑视图不存储实际的数据,每次查询时都需要动态执行底层SQL。而物化视图(Materialized View)则是将查询结果物理存储在数据库中,类似于一个缓存表,主要用于提升复杂查询的性能(可惜的是MySQL并不支持物化视图,而Oracle、PostgreSQL均是支持的)
3、视图的注意事项
· 在对视图本身进行创建或删除操作时只会影响视图本身,而不会影响基表中的数据
· 对视图中的数据进行修改或者修改基表中的数据会互相影响(通过视图修改数据时需要注意基表的表结构,比如基表有C字段不允许为NULL,而视图中并没有引用这个字段,那么通过视图去新增数据则会失败,因为视图看不到C)
· 物化视图中的数据无法进行修改,而对基表数据进行更新后,需要对物化视图进行更新操作,不同数据库有不同的更新机制可以选择
· 可以对物化视图创建索引进一步提升性能
· 视图过多后会使维护变得复杂,尤其是一些嵌套视图可读性差,容易变成潜在隐患
4、视图的管理
· 创建视图
#视图创建语法
#CREATE VIEW 视图名称 AS 查询语句
#针对单表创建视图
CREATE [definer = {user} ] VIEW view_name AS select * from table_name
#针对多表创建视图
CREATE VIEW my_view AS
SELECT e.employee_id,e.department_id,d.department_name FROM emps e JOIN depts d ON e.department_id=d.department_id;· 使用视图
在视图创建好以后直接使用查询语句查看视图即可
SELECT * FROM my_view #从视图中查询数据
· 修改视图
#使用ALTER修改 ALTER VIEW view_name AS SELECT ..... #使用REPLACE修改 REPLACE VIEW view_name AS SELECT ......
· 删除视图
DROP VIEW view_name
二、数据库触发器
触发器是一种由事件自触发并执行的数据库对象,比如当对某表进行 INSERT、UPDATE 或 DELETE 操作之前或之后,自动执行触发器里所定义的其他 SQL 语句。常见于数据同步的场景,保持表和表之间数据一致性,比如从学生表中删除某个学生时,自动删除成绩表里的分数信息。
1、触发器注意事项
在大部分互联网公司(特别是大规模高并发业务)的生产环境中往往有禁用触发器的规定,原因如下:
· 性能影响:触发器是同步执行的,如果逻辑复杂会拖慢原 SQL 执行速度。并且行级触发器在大批量更新时可能触发成千上万次,容易变成性能瓶颈。高并发下触发器执行成本不容易估算,甚至直接打爆数据库
· 调试难度:触发器逻辑隐藏在数据库内部,不容易被应用层发现,出错时排查比较麻烦。
基于上述两点原因,建议有数据同步、业务规则等逻辑放到 应用服务 或 消息队列(如 Kafka、RabbitMQ)中实现。如果确实需要数据自动化的动作,可以考虑使用 类似Canal等对binlog进行订阅的组件
2、触发器的管理
· 创建触发器
在MySQL中触发器为行级触发器,触发器会根据影响的行数执行多次,在PostgreSQL中还支持语句级别的触发器,语句级别触发器只会触发一次。另MySQL中的触发器只能作用于 INSERT、UPDATE 或 DELETE 这三种DML语句,PostgreSQL则支持通过Event Trigger创建DDL触发器,SELECT语句无法创建触发器
CREATE TRIGGER 触发器名
{BEFORE | AFTER} {INSERT | UPDATE | DELETE}
ON 表名
FOR EACH ROW #行级触发器,每一行数据发生变化都会执行一次触发器
[触发器主体SQL语句]示例
#插入新用户时自动写入日志表 CREATE TRIGGER trg_user_insert AFTER INSERT ON users FOR EACH ROW INSERT INTO user_logs(user_id, action, action_time)VALUES (NEW.id, 'insert', NOW());
三、数据库存储过程
存储过程是对一条或多条SQL语句的封装,一次编译可以多次使用,减少开发工作量。存储函数和存储过程的作用类似,区别在于自定义的存储函数一定会返回一个值,而存储过程不一定。虽然使用存储函数可以一定程度提高代码复用率,但是由于其移植性差(不同数据库编写的存储过程不互相兼容)、调试不方便、版本管理困难(表结构变化可能会导致存储过程失效)、服务端资源消耗厉害等问题,所以在一些大并发场景下不建议使用存储过程。
1、存储过程创建语法
CREATE [DEFINER|INVOKER] PROCEDURE 存储过程名称(IN|OUT|INOUT 参数名 参数类型...) COMMENT '注释信息' [characteristics ...] BEGIN 存储过程体 END
DEFINER:只有当前存储过程的创建者才能调用该存储过程
INVOKER:拥有当前存储过程访问权限的用户可以调用该存储过程
COMMENT:注释信息
IN:存储过程的默认参数,代表需要传递给存储过程的参数,参数可以有多个,用逗号分隔
OUT:存储过程执行完成以后客户端可以读取这个参数的返回值,相当于是存放在了一个变量中
INOUT:可以是输入参数也可以是输出参数
2、存储过程示例
delimiter ;; #使用delimiter临时改变分隔符,用//这样的符号也是可以的 create procedure 过程名() begin select AVG(salary) as avgsal from student; #过程主体,也就是需要使用到的SQL了 end ;; delimiter ; #声明回原本分隔符
#创建存储过程avg_salary(),返回所有员工平均工资 DELIMITER // CREATE PROCEDURE avg_salary() BEGIN SELECT AVG(salary) FROM employees; END // DELIMITER ; #带OUT的存储过程 #创建存储过程show_min_salary(),查看emps表中最低薪资,并通过OUT参数ms进行输出 DELIMITER // CREATE PROCEDURE show_min_salary(OUT ms DECIMAL) BEGIN SELECT MIN(salary) INTO ms FROM employees; END // DELIMITER ; #带IN的存储过程 #创建存储过程show_somenoe_salary(),查看emps表中某个成员薪资,并通过IN参数输入员工姓名 DELIMITER // CREATE PROCEDURE show_someone_salary(IN empname VARCHAR(10)) BEGIN SELECT salary FROM employees WHERE last_name= empname END // DELIMITER ;
3、调用存储过程
#调用无参数存储过程
call avg_salary();
#调用OUT参数存储过程
call show_min_salary(@ms);
#查看变量
SELECT @ms;
#调用IN参数存储过程
call show_somenoe_salary('tanglu');4、查看存储过程
SHOW PROCEDURE STATUS #查看实例下的所有存储过程 SHOW PROCEDURE STATUS LIKE '%proc_delete_node%' #根据条件查询 SHOW CREATE PROCEDURE hzins_mtkf.`proc_delete_node` #查看存储过程的创建语句


猜你喜欢

MySQL | Oracle Oracle教程(6)SGA\PGA\REDO核心参数调优
一、Oracle核心参数介绍1、SGASGA(System Global Area)是 Oracle 实例启动时分配的共享内存区域,所有连接到该实例的会话都共用这块内存,是整个数据库实例对外提供服务的...

MySQL | Oracle Oracle教程(5)数据泵备份教程与实战
一、数据泵介绍数据泵(Data Pump)是 Oracle 10g 开始引入的命令行逻辑备份与恢复工具。通过 expdp / impdp ,可以对所有数据库对象(模式、表数据、表空间等)进行高效导出和...
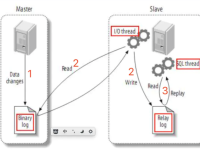
MySQL | Oracle MySQL教程(13)基于Position或GTID实现主从复制
一、MySQL主从复制概述主从复制是MySQL高可用与横向扩展的基础方案,其核心依赖于 MySQL 自身的 Binlog 机制。主节点的 Binlog 记录了数据库上所有的 DDL 与 DML 操作(...
MySQL | Oracle MySQL教程(12)锁的原理与常见锁问题处理
一、数据库锁的作用数据库锁主要用于解决并发问题,当并发操作发生时,数据库依靠锁来控制这些并发请求对资源(锁是针对资源而非事务)的访问规则,因为被上锁的资源不会被其他事务修改,因为可以保证事务之间的隔离...
MySQL | Oracle 【MySQL 8.0】MySQL 8.0新特性介绍与升级方法
一、MySQL 8.0主要新特性截至2023年12月,MySQL官方发布的稳定版为8.0.35,另有一个MySQL8.2为创新版,所以暂不做考虑· 快速新增/删除列虽然 MySQL 在8.0 以前就已...

文章评论