

PostgreSQL教程(12)基于流复制的主从集群
一、PostgreSQL 流复制概念
在PostgreSQL中,通过流复制(Streaming Replication)实现主从架构,保证数据安全性的同时提高读写性能与容灾能力。流复制的实现方式和MySQL主从复制非常类似,通过将主库产生的 WAL 日志以数据流的方式,实时、持续地传输给从库,从而保证主从数据库的数据一致性。由于是从物理层面复制的 WAL 日志,里面都是二进制数据,非逻辑 SQL 语句,整个效率非常高效。通过流复制形成的主从集群,可以满足数据库的高可用以及读写分离需求,并且可以一定程度的起到灾备与备份作用。
流复制的同步方式分为同步与异步两种,默认为异步模式,主库事务提交后无需等待从库确认,整体性能更好,但在故障时可能存在数据丢失风险;而同步方式下主库事务后提交必须等待从库确认 WAL 接收后才会继续执行事务,保证数据零丢失,但对性能略有影响。
二、PostgreSQL 流复制部署
以最简单的1主1从架构进行部署演示
1、主库配置
· 主库配置文件
由于流复制采用物理备份的方式,所以归档日志必须开启
vi postgresql.conf listen_addresses = '*' port = 5432 端口 max_connections = 1000 并发数 logging_collector = on #打开日志 log_directory = 'logs' #日志存放相对路径,在postgresql/data目录下 log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log' #日志命名格式 log_truncate_on_rotation = on #日志循环使用 shared_buffers = 512MB #PGSQL占用的内存空间 max_wal_size = 1GB min_wal_size = 80MB #归档配置 archive_mode = on #开启归档模式 archive_command = 'test ! -f /data/postgresql/archive/%f && cp %p /data/postgresql/archive/%f' #流复制配置 wal_level = replica #设置WAL日志为物理复制级别,如果需要逻辑复制或使用 pglogical则需设为 logical max_wal_senders = 10 #允许 WAL 日志被多少个从库读取,要大于等于从库数量 wal_keep_size = 512MB #WAL 保留策略,保证主库不会过早清理 WAL wal_sender_timeout = 60s #流复制超时时间,如果主库检测备库超时则认为从库不可用 wal_log_hints = on #hint bits 的更新也进入WAL日志,可以避免主从切换时数据不一致 #同步复制配置,如果开启同步复制建议至少2个从库,避免单从故障后主库hang住 #synchronous_commit = on #on代表同步复制;off则是异步,也是默认模式;除此中间还有几个模式也跟刷盘策略有关 #synchronous_standby_names = 'pgsql1,pgsql2' #同步模式下必须配置,指定同步复制的从节点名字,*代表all,可以通过primary_conninfo中application_name自定义
· 创建流复制用户并授权
#创建repluser用户给赋予replication权限 create user repluser replication password '123456789';
· 配置主库白名单文件
vi pg_hba.conf host replication repluser 192.168.159.0/24 md5
· 重启主库,检查配置是否生效
show wal_level; show archive_mode; show archive_command; ps aux | grep archiver 查看是否有归档进程 ls /data/postgresql/archive/ #查看归档目录是否有日志
2、从库配置
· 同步数据
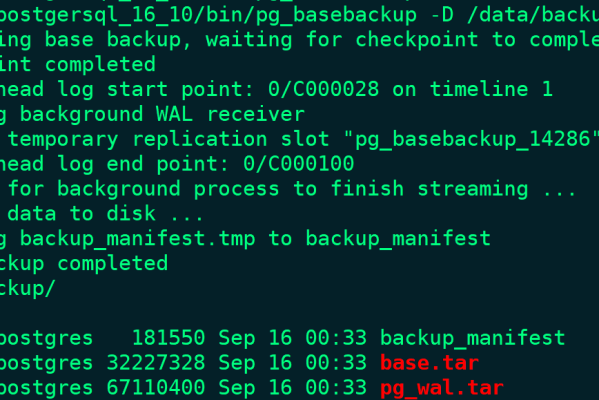
在从节点通过物理备份工具pg_basebackup拉取主库所有数据(全量备份+WAL日志)到本地数据目录
pg_basebackup -D /data/postgresql/data/ -Fp -P -R -h192.168.0.103 -p5432 -Urepluser #-D:指定数据目录,需要为空 #-F: 使用plain(目录/文件)拉取数据 #-P:显示数据传输进度 #-R:创建 standby.signal 文件并把连接信息(primary_conninfo)写入postgresql.auto.conf 中,数据库启动时就会自动进入 standby/流复制模式 #-h:指定主库地址 #-U:指定拥有复制权限的用户
· 启动从库
启动后可以查看walreceiver进程是否启动
/usr/local/postgresql/bin/pg_ctl -D /data/postgresql/data/ start ps aux | grep walreceiver
· 验证同步状态
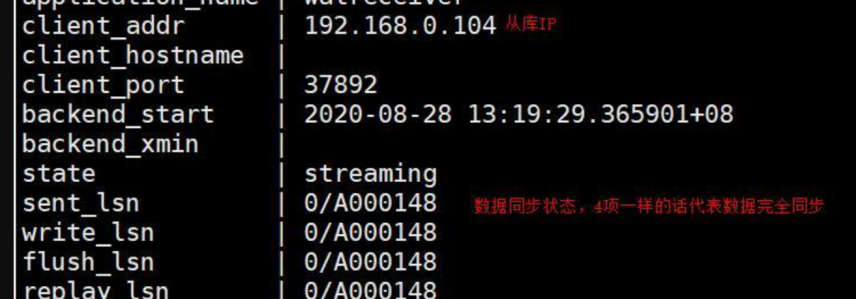
在主库插入数据,然后在从库查看是否同步。另外从库会自动变成只读模式,无法插入数据。在主库通过pg_stat_replication视图可以查询主从同步状态,包含同步(sync)、异步(async)、potential(潜在同步,当同步库故障时升级它升级为sync)、从库地址、WAL日志位置等
\x #类似于MySQL的\G,让显示更友好 select * from pg_stat_replication; #这里可以看出主从同步还是异步

3、节点扩容
新节点只需要和主从部署一样的操作即可,过程略
三、PostgreSQL主从切换
从 PostgreSQL12 版本开始,可以通过promote指定来对主从角色进行切换。此命令会让从库从只读模式直接切换为读写模式,整个过程无需停止从库的服务。所以当主库发生故障不可用或者需要手动进行主从切换后可按如下方法操作
· 关闭原主库
pg_ctl -D /data/postgresql/ stop -m fast
· 确认节点角色
# 返回 true 表示从库 SELECT pg_is_in_recovery();
· 切换角色
# 切换角色 pg_ctl -D /data/postgresql/ -l logfile promote
· 确认节点角色
# 返回 false 表示主库 SELECT pg_is_in_recovery();
四、PostgreSQL 自动化高可用
由于流复制只能保证数据同步,无法实现自动故障切换,如果要实现主备集群的自动化高可用,通常需要搭配一些第三方组件来实现完整的 HA 架构。常见选择如下
· repmgr
PostgreSQL 原生流复制管理工具,支持自动或手动故障转移以及节点扩容,可以很好适用于中小型集群
· pg_auto_failover
由 CitusData 开发,通过监控节点(monitor)对数据节点(primary/secondary)的状态进行管理,支持自动 failover。适用于对架构复杂度要求不高,但又需要自动化HA的场景



猜你喜欢

MySQL | Oracle Oracle教程(6)SGA\PGA\REDO核心参数调优
一、Oracle核心参数介绍1、SGASGA(System Global Area)是 Oracle 实例启动时分配的共享内存区域,所有连接到该实例的会话都共用这块内存,是整个数据库实例对外提供服务的...

MySQL | Oracle Oracle教程(5)数据泵备份教程与实战
一、数据泵介绍数据泵(Data Pump)是 Oracle 10g 开始引入的命令行逻辑备份与恢复工具。通过 expdp / impdp ,可以对所有数据库对象(模式、表数据、表空间等)进行高效导出和...
MySQL | Oracle MySQL教程(13)基于Position或GTID实现主从复制
一、MySQL主从复制概述主从复制是MySQL高可用与横向扩展的基础方案,其核心依赖于 MySQL 自身的 Binlog 机制。主节点的 Binlog 记录了数据库上所有的 DDL 与 DML 操作(...
MySQL | Oracle MySQL教程(12)锁的原理与常见锁问题处理
一、数据库锁的作用数据库锁主要用于解决并发问题,当并发操作发生时,数据库依靠锁来控制这些并发请求对资源(锁是针对资源而非事务)的访问规则,因为被上锁的资源不会被其他事务修改,因为可以保证事务之间的隔离...
MySQL | Oracle 【MySQL 8.0】MySQL 8.0新特性介绍与升级方法
一、MySQL 8.0主要新特性截至2023年12月,MySQL官方发布的稳定版为8.0.35,另有一个MySQL8.2为创新版,所以暂不做考虑· 快速新增/删除列虽然 MySQL 在8.0 以前就已...

文章评论