


PostgreSQL教程(6)VACUUM碎片清理与并行查询特性
一、VACUUM 机制介绍
1、VACUUM作用
VACUUM是PostgreSQL中的碎片维护机制,用于清理和回收无效数据。由于 PostgreSQL 的 MVCC 机制实现原理与MySQL不同,它并不是把历史版本存在 Undo Log中由后台线程自动清理。而是将被 DELETE 或 UPDATE 的数据行标记为 dead tuple(死元组),然后通过 VACUUM 机制进行清理。如果一个表中数据更新频繁,就需要不定期的通过VACUUM操作进行碎片清理,回收资源。
2、自动 VACUUM
PostgreSQL 默认已经启用 autovacuum 守护进程,它会根据表的更新比例、dead tuples 数量自动触发 VACUUM。配置文件中相关参数如下:
autovacuum = on #默认开启autovacuum autovacuum_vacuum_scale_factor = 0.3 #表中产生了多少比例的 dead tuples会触发 autovacuum,默认0.2表示20% autovacuum_analyze_scale_factor = 0.2 #表中有多少数据行执行了DML操作会触发 autovacuum,默认0.1表示10%
3、手动 VACUUM
通常依赖自动VACUUM即可,因为手动进行 VACUUM 相当于进行了表重建+索引重建,属于很重量级的操作。只有当大表发生频繁更新后才可能需要手动 VACUUM 进行空间回收。
下面通过插入数据、删除数据、回收碎片的一系列操作来看看VACUUM的效果:
1、建库建表并插入数据
create database pgstudy \c pgstudy pgstudy=# CREATE TABLE t1 ( id SERIAL PRIMARY KEY, info TEXT ); pgstudy=# INSERT INTO t1 (info) SELECT 'row ' || g FROM generate_series(1, 1000000) g;
2、查看当前表大小
pgstudy=# SELECT pg_size_pretty(pg_relation_size('t1')) AS size;
size
-------
42 MB
(1 row)3、删除表中数据
pgstudy=# delete from t1
4、再次查看表大小,可以发现表大小没有变化,资源被浪费
pgstudy=# SELECT pg_size_pretty(pg_relation_size('t1')) AS size;
size
-------
42 MB
(1 row)5、查看表的状态信息
select * from pg_stat_user_tables where relname = "t1" n_live_tup #表中有效数据行 n_dead_tup #表中没有回收的数据行
6、进行碎片清理
pgstudy=# vacuum t1
7、再次查看表中数据状态和表大小,已经有效的回收了碎片
pgstudy=# SELECT pg_size_pretty(pg_relation_size('t1')) AS size;
size
---------
0 bytes
(1 row)二、并行查询特性
1、并行查询介绍
PostgreSQL 从 9.6 版本开始支持并行查询特性,并且在之后的版本不断优化,在 15、16 版本中已经比较成熟。通过并行查询可以将一个复杂的 SQL 同时交给多个后台 worker 进程一起完成,加快查询速度,特别是对大表全表扫描、大量聚合、复杂 join 的场景。在 PostgreSQL 中并行查询是由优化器来决定是否使用的,不需要人为干涉,当优化器认为需要并行查询时会通过 Gather节点来启动并管理多个worker进程,由这些 worker 进程去进行扫描表或索引、做 join、聚合等操作。最后 Gather 节点再把这些 worker 进程返回的数据进行汇总,交给上层计划节点继续处理。
2、并行查询配置
主要参数都在 postgresql.conf 或 session 中设置
max_parallel_workers_per_gather = 4 #每个 Gather 节点最多能用的 worker 数,默认 2,通常建议设置 4-8 max_parallel_workers = 8 #全局最大并行 worker 数(默认 8) parallel_setup_cost = 1000 #启动并行 worker 的固定开销,默认 1000 parallel_tuple_cost = 0.1 #每个 tuple 通过 Gather 节点传递的成本,默认 0.1 min_parallel_table_scan_size = 1024M #表体积至少要达到多大才进行并行查询,默认8M min_parallel_index_scan_size = 128M #索引体积至少要达到多大才进行并行查询,默认512K
3、查看并行查询
执行计划里如果出现如下关键词代表使用到了并行查询
Gather (cost=1000.00..20000.00 rows=1000000 width=8) Workers Planned: 4 -> Parallel Seq Scan on big_table ...
· Workers Planned:在 EXPLAIN 中看到的 “Workers Planned: N”,表示预计使用多少 worker



猜你喜欢

MySQL | Oracle Oracle教程(6)SGA\PGA\REDO核心参数调优
一、Oracle核心参数介绍1、SGASGA(System Global Area)是 Oracle 实例启动时分配的共享内存区域,所有连接到该实例的会话都共用这块内存,是整个数据库实例对外提供服务的...

MySQL | Oracle Oracle教程(5)数据泵备份教程与实战
一、数据泵介绍数据泵(Data Pump)是 Oracle 10g 开始引入的命令行逻辑备份与恢复工具。通过 expdp / impdp ,可以对所有数据库对象(模式、表数据、表空间等)进行高效导出和...
MySQL | Oracle MySQL教程(13)基于Position或GTID实现主从复制
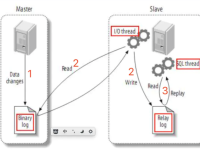
一、MySQL主从复制概述主从复制是MySQL高可用与横向扩展的基础方案,其核心依赖于 MySQL 自身的 Binlog 机制。主节点的 Binlog 记录了数据库上所有的 DDL 与 DML 操作(...
MySQL | Oracle MySQL教程(12)锁的原理与常见锁问题处理
一、数据库锁的作用数据库锁主要用于解决并发问题,当并发操作发生时,数据库依靠锁来控制这些并发请求对资源(锁是针对资源而非事务)的访问规则,因为被上锁的资源不会被其他事务修改,因为可以保证事务之间的隔离...
MySQL | Oracle 【MySQL 8.0】MySQL 8.0新特性介绍与升级方法
一、MySQL 8.0主要新特性截至2023年12月,MySQL官方发布的稳定版为8.0.35,另有一个MySQL8.2为创新版,所以暂不做考虑· 快速新增/删除列虽然 MySQL 在8.0 以前就已...

文章评论